


Unlike other blogs, I don't have any recent event to be proud of. But still... Ask me anything!
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3690 |
| 2 | jiangly | 3647 |
| 3 | Benq | 3581 |
| 4 | orzdevinwang | 3570 |
| 5 | Geothermal | 3569 |
| 5 | cnnfls_csy | 3569 |
| 7 | Radewoosh | 3509 |
| 8 | ecnerwala | 3486 |
| 9 | jqdai0815 | 3474 |
| 10 | gyh20 | 3447 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 163 |
| 4 | TheScrasse | 159 |
| 5 | nor | 157 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 152 |
| 8 | Petr | 146 |
| 8 | orz | 146 |
| 10 | pajenegod | 145 |
→ Find user
→ Recent actions





Hello, Codeforces! Or, as we like to say in Romania: Sus Sus Sus, ca la Strehaia tată!
I am glad to finally invite you to participate in Codeforces Round 875 (Div. 1) and Codeforces Round 875 (Div. 2), which will start on May/28/2023 17:35 (Moscow time). In both divisions, you will be given 6 problems and 2 hours and 30 minutes to solve them.
The problems were authored and prepared by Andrei_ierdnA, Doru, Gheal, IacobTudor, LucaLucaM, RedstoneGamer22, SlavicG, Sochu, alecs, andrei_boaca, anpaio, lucaperju, valeriu and me ( tibinyte ).
I would like to thank:
- errorgorn, for his wonderful coordination.
- irkstepanov for further help with logistics of organization.
- Alexdat2000 for russian translation.
- alin_gb18, rsj, dario2994
jampm, Psychotic_D, prvocislo
cristi_tanase, atodo, BucketPotato
Moolamp, magnus.hegdahl, Gary2005
Geanina_the_Great, 555, PurpleCrayon
Um_nik, gamegame, conqueror_of_tourist, penguinhacker, AlexLorintz, lucri, _Vanilla_, Vladithur, status_coding, Luci_badea1000, bycicle, myvaluska for testing the round and providing useful feedback.
- freak93 for no morning refreshment.
- MikeMirzayanov for great platforms, codeforces and polygon!
Scoring Distribution
div 2: $$$500-750-1250-1750-2500-3000$$$
div 1: $$$500-1000-1750-2250-3000-3500$$$
The editorial has been published here!
And here are our winners!
| # | Div 1 | Div 2 |
|---|---|---|
| 1 | Ormlis | kotrin |
| 2 | 1a2b3c4 | CLOCKS_PER_SEC |
| 3 | dorijanlendvaj | IHatePaiu |
| 4 | tourist | Lihwy |
| 5 | Radewoosh | VietCek |
To all law authorities, this is an admission of guilt.
Today I competed in Codeforces Round 870 (Div. 2) and I made the unethical move of copying the solution of problem B from some telegram channel. I was foolish to do such a dick move and would like to publicly apologise for my actions.
I would request to be disqualified ( or receive a negative rating change ) because I definitely don't deserve my +11 delta. There are lots of people who worked hard in this contest, but still got a negative rating change.
Cordially,
tibinyte
The Cartesian Tree is a useful concept for solving some problems which revolve mainly about thinking of the range of maximality of elements. It also provides a sort of "persistance" to the algorithm of monotonic stack, if you will. In this blog, we will learn what a Cartesian Tree is, how to construct one and solve some related problems to strengthen our understanding. Let's begin!
What is a Cartesian Tree?
Let's consider an array $$$a$$$ where all values are distinct. The Cartesian Tree for the array $$$a$$$ is a binary labeled tree build recursively from the function $$$get(l,r)$$$ which constructs our desired tree from the subarray $$$l...r$$$.
Now let's define $$$get(l,r)$$$
First root the tree at index $$$i$$$ such that $$$a_i = min(a_l,a_{l+1},...,a_r)$$$. Note that because all values are distinct, $$$i$$$ will always be unique.
The aforementioned index will become the root of the Cartesian Tree. It's left and right subtrees will be recursively generated by $$$get(l,i-1)$$$ and $$$get(i+1,r)$$$ respectively. If $$$i=r$$$ we will ignore the right subtree, if $$$i=l$$$ we will ignore the left subtree.
As an example, consider $$$a=[9,3,7,1,8,12,10,20,15,18,5]$$$. After calling $$$get(1,11)$$$, we get the following tree:
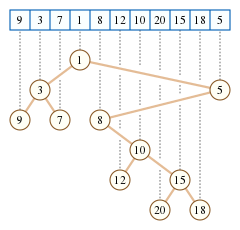
picture from here
By construction, the Cartesian Tree for an array $$$a$$$ where all values are distinct is always unique. Usually, when there can be repeating values, we will construct the Cartesian Tree in the same manner as before, but we will build it from the pairs {$$$a_i, i$$$}.
The above process can be easily simulated for building a Cartesian Tree in $$$O(nlogn)$$$ using a range minimum query.
Properties of the Cartesian Tree
- Heap: It has a min/max heap structure
- Corollary: Let $$$S_i$$$ be a set where $$$x \in S_i$$$ if and only if there exists $$$1 \le l \le i \le r \le n$$$ such that $$$min(l...r)=x$$$. If we traverse the path from node $$$i$$$ to the root, we will get all values in $$$S$$$ in decreasing order.
- Inorder Completeness: Each subtree represents a range in the original array
- Equivalence to RMQ: Consider $$$2$$$ nodes $$$(i,j)$$$. Let $$$x$$$ be their lca in the Cartesian Tree. We can show that $$$x = min(i...j)$$$.
Why?
Note that by using the last claim we can easily support range minimum query operations on the Cartesian Tree.
Also note that the second claim allows us to build a cartesian tree in $$$O(n)$$$, we can find the parent of each index using monotonic stacks.
Yet Another Array Counting Problem
Let's start with a problem authored by my friend Gheal.
This problem asks us, given an array $$$a$$$, to count the number of arrays $$$b$$$ such that for any subarray, the position of the maximum value is the same in both arrays, given that if there are multiple maximums, we take leftmost. We can easily note that this is equivalent to counting arrays $$$b$$$ for which their Cartesian Tree has the same structure as the Cartesian Tree for $$$a$$$.
And here goes the solution, let $$$dp_{i,j}$$$ hold the number of arrays $$$b$$$ that yield the same Cartesian Tree as the subtree of node $$$i$$$ and the attributed value for the node $$$i$$$ is at most $$$j$$$. We can note that our answer is $$$dp_{root,m}$$$. To calculate we either chose the value of our current node to be $$$j$$$ or rely on $$$dp_{i,j-1}$$$. Thus we can get quick tranisitons:
An implementation of this idea can be viewed here.
Comfortably Numb
Let's build the max Cartesian Tree of the input array. Let's see what the task changes to when switching the array to its Cartesian Tree. It turns out we need, for each root to find $$$max(a_{node} \oplus x \oplus y)$$$ where $$$x$$$ is the prefix xor of some node from the left subtree and $$$y$$$ is the prefix xor of some node in the right subtree ( including the current root ). We can precompute prefix xors and iterate over the smaller subtree and the task becomes finding maximum xor pair which can be done with a trie. Since we merged smallest into largest the complexity is $$$O(n \cdot logn \cdot logM)$$$ where $$$M$$$ is the maximum value in the input.
An implementation of this idea can be viewed here
A harder problem, Vaporeon
Since the statement is only available in romanian, I will translate it for you.
Consider an array with $$$a$$$ with only distinct values ( the problem allows repeted elements, but figuring all the details about making the following solution work on repeating values is left as an exercise to the reader ).
We call $$$f(x)$$$ the depth in the Cartesian Tree of index $$$x$$$. We need to tolerate the following $$$2$$$ operations:
Update: $$$swap(a_i,a_{i+1})$$$
Query: range sum on $$$f$$$
Let's reformulate the problem a little. For each index $$$a_i$$$ we will find the largest range where $$$a_i$$$ is maximum. The depth of the Cartesian Tree of some index is now just the number of intervals that pass through this index. Let's see how we can update those intervals when tolerating a swap update.
We will keep $$$2$$$ arrays of treaps $$$l$$$ and $$$r$$$ where the treap at index $$$l_i$$$ holds all the segments that end at $$$i$$$ ( as left endpoint ) and $$$r_i$$$ keeps all segments ending at $$$i$$$ ( as right endpoint ). WLOG assume we are doing $$$swap(a_i, a_{i+1})$$$ and $$$a_i > a_{i+1}$$$. Now we will analyze how $$$l_{i+1},l_{i+2},r_i,r_{i-1}$$$ change after an update:
$$$l_{i+1} = \varnothing$$$
$$$l_{i+2} = l_{i+1} \cup l_{i+2}$$$
$$$r_{i-1} = r_{i-1} \cap [1,2,3,...,a_{i+1}]$$$
$$$r_i = r_{i-1} \setminus [1,2,3,...,a_{i+1}]$$$
With a bit of extra analyzing we can note that all these operations are doable because $$$l$$$ and $$$r$$$ are kept as treaps and we always merge smaller values with larger values. After performing all these operations, all we are left to do is update the range of $$$a_{i+1}$$$ which we can do via binary searching on a segment tree in $$$O(logn)$$$ and inserting the new range in the corresponding treaps.
Since every update we do a split and a merge on the aforementioned treaps and update a single range, the complexity will be $$$O(logn)$$$. And at the same time there are $$$O(1)$$$ modifications in $$$f$$$ so we can update our range sum data structure fast.
An implementation of this idea can be viewed here.
Constellation 3 ( JOISC 2020 )
We are given a binary matrix. It is known that each column of the binary matrix is white for $$$a_i$$$ cells and then it's just black. We are also given some points with coefficients and are asked to activate a subset of points with maximal cost such that no $$$2$$$ points can see eachother. We consider $$$2$$$ points being able to spot each other iff there exists a black reactangle containing both.
Let's say we took a star on the same Y-coordinate as "smallest" black column ("tallest" building). We can notice that this would imply a restriction of the type "from now on we are only allowed to take stars that are at most $$$a_i$$$ units tall". This is because we will always be able to see that star otherwise.
It turns out this observation is enough for a polynomial solution based on tree DP. This way, we build the min Cartesian Tree and let $$$dp_{i,j}$$$ be the maximum cost of a subset consisting only of nodes from the subtree of $$$i$$$ and my restriction forces me to only take stars at most $$$j$$$ units tall. Transitions are very easy, we can just decide weather we take a star on current column or not. As a detail, if we don't take any star, at least one of the children needs to go at most $$$a_i$$$ units tall restriction, because we would see the 2 stars because they would both pass through $$$i$$$. For a better understanding of this solution, I recommend reading my code.
To achieve a faster solution we must exploit the Cartesian Tree and reduce the problem to something else. The magic reduction uses the corollary of the heap property. Thus we can find that each star's visibility can be expressed as a path from its columns node to the root in the Cartesian Tree. What's more exciting is using the fourth propriety, one can note that $$$2$$$ stars intersect iff their paths intersect, because they can both see the minimum in their range, meaning they can see everything else.
Thus our problem is reduced to chosing some disjoint chains in a tree such their coefficient sum is maximum. Fun fact, this new problem appeared on infoarena before and can be viewed here.
To solve it we just keep in $$$dp_i$$$ the maximum coefficient sum such that all used chains are fully included in the subtree of $$$i$$$. To calculate it we consider each chain that ends in node $$$i$$$ and try to include it in our solution. We need to add all $$$dp$$$ values that are directly attatched to the used chain, which can be done using a bit or any data structure that can support sum on chains with point updates.
For finding the chains we can just use binary lifting, thus our final time complexity is $$$O(nlogn)$$$.
An implementation of this idea can be viewed here.
And last but not least, thanks to Gheal, valeriu, SlavicG for reviewing this blog.

{kind=link}
Hello, codeforces!
In my last round, that is CodeTON Round 3, I set a problem no one could solve in the competition. It somehow displays as $$$2100$$$, which I think is not accurate? Can someone review this, please ( MikeMirzayanov ) ?
It's strange as $$$G$$$ is rated as $$$3300$$$.
UPD: fixed
Hello, Codeforces! Or, as we like to say in Romania: Nu îmi amintesc să fi adresat întrebări, Codeforces!
I am glad to finally invite you to participate in CodeTON Round 3 (Div. 1 + Div. 2, Rated, Prizes!), which will start on Nov/06/2022 17:35 (Moscow time). You will be given 8 problems and 2 hours and 30 minutes to solve them. It is greatly recommended to read all the problems, statements are short and straight to the point.
I would like to thank:
- Artyom123 for prodigious coordination.
- AquaMoon, mejiamejia, ugly2333, Ecrade_ for huge help in preparation and authoring one of the tasks.
- errorgorn for being a VIP-tester.
- Lemur95, Gheal, Perpetually_Purple, Everule, IacobTudor, andrei_boaca, lucri, AlperenT, Kuroni, prabowo, lis05, Alon-Tanay, jeroenodb, Juve45, denis2111, Brodicico, Fanurie, huangzirui, satyam343, tfg, Sugar_fan, SlavicG, Vladithur,KrowSavcik, kevinxiehk, sharkycode,Alan, TimDee, Rhodoks, dannyboy20031204,TomiokapEace, Qingyu, lxlxl, ChthollyNotaSeniorious,PinkieRabbit, jerryliuhkg, valeriu, Chenyu_Qiu, jampm, izlyforever, njupt_lyy, RUSH_D_CAT,azureAmarantine, Erkhemkhuu, wh030115,ak2006, dorijanlendvaj, spookywooky, arvindf232, absi2011, AlexLorintz for testing the round and providing invaluable feedback.
- freak93 for morning refreshment.
- MikeMirzayanov for great platforms, codeforces and polygon!
Scoring Distribution: 500-750-1250-1750-2250-2500-3250-3500
The editorial has been published here!
And here are our winners!
- Benq
- zh0ukangyang
- WYZFL
- MagicalFlower
- feecIe6418
- QuietBeautifulThoughts
- p_b_p_b
- conqueror_of_tourist
- jiangly
- tourist
And here is the information from our title sponsor:

Hello, Codeforces!
We, the TON Foundation team, are pleased to support CodeTON Round 3.
The Open Network (TON) is a fully decentralized layer-1 blockchain designed to onboard billions of users to Web3.
Since July, we have been supporting Codeforces as a title sponsor. This round is another way for us to contribute to the development of the community.
The winners of CodeTON Round 3 will receive valuable prizes.
The first 1,023 participants will receive prizes in TON cryptocurrency:
- 1st place: 1,024 TON
- 2–3 places: 512 TON each
- 4–7 places: 256 TON each
- 8–15 places: 128 TON each
- …
- 512–1,023 places: 2 TON each
We wish you good luck at CodeTON Round 3 and hope you enjoy the contest!
Since goals are very important in any individual's life, I decided to set a goal for myself. The target is to set 100 problems until I quit cp.
Current progress: 40
| # | Date | Comments | Feedback | |||
|---|---|---|---|---|---|---|
| 1 | July 2021 | Summer 2021 Round 1 | First problem I ever set. It asks you to find the number of bubble sort iterations to sort a given array | Good Bad | ||
| 2 | July 2021 | Summer 2021 Round 1 | This problem is a very standard problem which asks to find sum of gcds across all subarrays | Good Bad | ||
| 3 | July 2021 | Summer 2021 Round 1 | This is a quite ok digit dp problem which asks finding the number of numbers s.t. the maximum frequency of some digit — minimum frequency of some digit = $$$k$$$, where $$$k$$$ is given | Good Bad | ||
| 4 | July 2021 | Very standard problem that asks to find how many subsets of $$$a$$$ are anagrams of $$$b$$$ | Good Bad | |||
| 5 | July 2021 | Summer 2021 Training round | Very standard problem about stirling numbers of the second kind | Good Bad | ||
| 6 | July 2021 | Summer 2021 Training round | Very standard problem asking for sum of gcds across all arrays of length $$$n$$$ and values in range $$$[1,m]$$$ | Good Bad | ||
| 7 | August 2021 | Summer 2021 Round 2 | Problem asking for number of subarrays with given median | Good Bad | ||
| 8 | August 2021 | Summer 2021 Round 2 | Problem asking for number of subarrays such that if it contains a color, it must contain every color of that kind | Good Bad | ||
| 9 | November 2021 | Autumn 2021 Round 2 Div 2 | A simple greedy problem | Good Bad | ||
| 10 | November 2021 | Autumn 2021 Round 2 Div 1 | I am only a coauthor in this task. The initial problem idea was by Gheal. A quite standard problem on PIE | Good Bad | ||
| 11 | December 2021 | Autumn 2021 Training round | This problem is a math problem that turned into a troll problem with partial scoring. I don't take credit for its idea, only for making it appear in a contest :clown: | Good Bad | ||
| 12 | December 2021 | Autumn 2021 Training round | Educational problem on d&c dp optimization | Good Bad | ||
| 13 | January 2022 | Winter 2022 Round 1 Div 1 | A nice problem, but my sqrt optimizations were just overkill since very simple solutions were using just PIE. I felt bad after finding out all my work optimizing the dp calculations was useless :( | Good Bad | ||
| 14 | February 2022 | CookOff | You set the cancer dp I couldn't solve. First and hardest problem I set on codechef | Good Bad | ||
| 15 | March 2022 | Lunchtime | A quite simple problem about both FFT and PIE. Since I didn't know FFT when I submited this problem on codechef, I'd like to mention Um_nik for improving my initial solution | Good Bad | ||
| 16 | March 2022 | Spring 2022 Round 1 Div 1 | It's a quite simple dp problem with an optimization | Good Bad | ||
| 17 | March 2022 | Spring 2022 Round 1 Div 2 | Quite straightforward couting problem with sieve optimization | Good Bad | ||
| 18 | March 2022 | Spring 2022 Round 1 Div 2 | Quite straightforward problem on monotonic stack | Good Bad | ||
| 19 | April 2022 | Starters 35 | Very cancer dp... It's good to make your enemies hate you more tho... | Good Bad | ||
| 20 | April 2022 | Starters 34 | I think it's one of my best easy problems | Good Bad | ||
| 21 | July 2022 | Lunchtime | Very similar statement to the one in Mex Pairs. Here we write an obvious dp and optimize it in a very interesting way | Good Bad | ||
| 22 | July 2022 | Round #804 | First problem I set on codeforces. My initial solution was $$$O(vmax \cdot log^2)$$$, but thanks to valeriu, it was reduced to $$$O(vmax \cdot log)$$$. I think it's one of my best problems | Good Bad | ||
| 23 | November 2022 | Round 3 | In my opinion, it's a very good D2B problem, solution combines a simple observation with a not so trivial optimization to keep the balance | Good Bad | ||
| 24 | November 2022 | Round 3 | I don't know why this problem was hated in the rate problem section, I think it's a good task that requires both some thinking and implementation | Good Bad | ||
| 25 | November 2022 | Round 3 | This task was added one day before the competition. It looked a good difficulty jump from C, but the distance to E was a bit too large. I apologize for this | Good Bad | ||
| 26 | November 2022 | Round 3 | After realizing how to compute the cost in a smart and flexible way, you can easily use a BIT to solve it | Good Bad | ||
| 27 | November 2022 | Round 3 | I think it's one of the best tasks in the contest, there are lots of solutions to it, mostly all at the same difficulty level. There also exists a $$$O(nlog^2n)$$$ solution, which I have implemented, but we used the $$$O(n^2)$$$ version to fit for $$$F$$$ position | Good Bad | ||
| 28 | November 2022 | Round 3 | It has a hidden refference, but leaving that behind, I think it's a quite nice counting task, and the solution is very unexpected | Good Bad | ||
| 29 | November 2022 | Round 3 | First problem I set on codeforces that didn't have any solves during the official contest. It is supossed to be a hard problem with a quite long implementation, but looking at upsolving submissions, implementation can actually be quite short :) | Good Bad | ||
| 30 | March 2023 | Finally setting on codechef again :) Yet another counting problem that almost went unsolved ( which is very surprising ). Am I too evil to ask variable mod FFT? Do people template variable mod FFT? I don't know. Orz jeroenodb first and only solve to this problem xD | Good Bad | |||
| 31 | May 2023 | A problem I created because we desperately needed a problem for D2B position. I don't think it's great but not bad either. | Good Bad | |||
| 32 | May 2023 | A problem that was intended to be in CodeTON Round 3, but we didn't need it there so we used it here. I came up with this problem while I was in car xD | Good Bad | |||
| 33 | August 2023 | Junior challenge 2023 | Best statement of 2023. Find sum of $$$choose(n,i) \cdot i^k$$$, $$$n \le 10^9, k \le 5000$$$ | Good Bad | ||
| 34 | August 2023 | Junior challenge 2023 | This problem was intended to be in CodeTON round 3 as D, but was removed few days before the competition. This version is however buffed. | Good Bad | ||
| 35 | October 2023 | RCPCamp 2023 Iasi day | This shares a similar statement to Doping, but is much easier. | Good Bad | ||
| 36 | December 2023 | Codeforces Round 915 (Div. 2) | Initial name was Adam Lying Face :( | Good Bad | ||
| 37 | December 2023 | Codeforces Round 915 (Div. 2) | I was expecting this to be as hard as E | Good Bad | ||
| 38 | December 2023 | Codeforces Round 915 (Div. 2) | Used to have some funny refference and a nice drawing but some magician removed both of them. | Good Bad | ||
| 39 | December 2023 | Codeforces Round 915 (Div. 2) | Was intended to be D1B in round #875. We ended up removing it because it was too hard. | Good Bad | ||
| 40 | December 2023 | Stelele informaticii 2023 | Probably D1B~C | A rejected proposal from round 875. | Good Bad |
A — Indirect Sort
Authors: mejiamejia, Ecrade_
Solution
Code (Ecrade_)
Rate Problem
B — Maximum Substring
Author: tibinyte
Solution
Code (tibinyte)
Rate Problem
C — Complementary XOR
Author: tibinyte
Solution
Code (tibinyte)
Rate Problem
D — Count GCD
Author: tibinyte
Solution
Code (tibinyte)
Rate Problem
E — Bracket Cost
Author: tibinyte
Solution
Code (tibinyte)
Rate Problem
F — Majority
Author: tibinyte
Solution
Code (tibinyte)
Rate Problem
Challenge: Solve the problem in $$$O(nlog^2)$$$ or $$$O(nlog)$$$ ( modulo is prime )
Solution
G — Doping
Author: tibinyte
Solution
Solution 2
Code (tibinyte)
Rate Problem
H — BinaryStringForces
Author: tibinyte
Solution
Code (tibinyte)
Rate Problem
#LeafTON
Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: May/16/2024 20:48:37 (k3).
Desktop version, switch to mobile version.
Supported by
