


Hi all!
I'm happy to invite everyone to a combined for Div.1 and Div.2 Mail.Ru Cup 2018 Round 2, that is starting at this time: Nov/10/2018 17:35 (Moscow time). The problems were prepared by Kuyan and Jacob. Thanks to cdkrot and 300iq for coordination and help in preparation.
Also huge thanks to majk, Lewin, vintage_Vlad_Makeev, demon1999 for testing, and also to MikeMirzayanov for Codeforces and Polygon platforms.
This round is the second round in the new championship called Mail.Ru Cup, you can learn more about it following the link. The round will be rated for everybody!
The championship feature the following prizes:
- First place — Apple MacBook Air
- Second and third place — Apple iPad
- Fourth, fifth, sixth places — Samsung Gear S3
- Traditionally, the top 100 championship participants will get cool T-shirts!
In each round, top 100 participants get prize points according to the table. The championship's result of a participant is the sum of the two largest results he gets on the three rounds.
There will be 7 problems for two and a half hours. The scoring will be available later.
I hope you will like the problems and wish you a rating increase!
UPD1: Scoring distribution:
500 1000 1500 2250 2750 3500 4000
The round is over, congratulations to the winners!
The current results of Mail.Ru Cup (summing up the two rounds) are published.
The analysis is also published.







Is there any AI Cup this year?
Hi! Russian AI Cup will be started in December.
Memes and more memes . . .
I guess you posted the wrong meme at the wrong time.
NOIP2018(National Olympiad in Informatics in Provinces) is being held in China now.So we will miss a great contest.What a pity!
Cleshes with Asia champions league-final
Very few users registered for this round :\
why would my second hacking attempt gets counted if its the same input to the same person ?
I just pressed backward in the browser and accedintally it got sent again :(
you would get "wrong answer on hack 1" if you submit code that doesn't pass the same test.
nah I'm the one hacking B) but my hacking attempt got sent twice accedintally
How to solve C,D,E?
Cool problems btw
E. Binary search for answer, and use dp[i=we can only take values i...n][j=there is at least j values <= mid] = minimal number of segments.
any idea what pretest 5 of C might be?
In got WA on 5 by only considering cases where the interval of lucky days of Bob is to the right of the interval of lucky days of Alice (in the optimal case). Not sure if this will help you...
(After considering cases where the interval is to the left I got WA on pretest 8 :( )
In case of such a scenario, I swapped Alice and Bob's info and performed my calculation in the same way. So, I think I handled that.
If I had 10 more seconds I think I would have solved D! ouch
Also, how do you solve C?
If I had an undefined number of seconds I would have solved F... I'm getting WA for some unknown reason.
never mind, i wouldn't have solved it with 10 extra seconds either
probably 10 more minutes
My solution for C.
I'll try explain as best as I can. Pretend array a is fixed. You can offset b by increments of gcd(ta, tb) relative to a (since the arrays are periodic). Start with the offset such that la - offset ≤ lb and la - offset is as close to lb as possible. Now push a rightwards increment by increment and check and store how many lucky days are shared each time. As soon as the number of shared lucky days stops increasing, break and print the maximum number of shared lucky days. Maybe this could be done with ternary search too, but my linear search was well under the time limit.
In D pretest 8 is something like
Unfortunately, I've came up with this too late.
fuck :)
Fuck indeed
Can you please explain your C
Assume la < lb (swap a and b otherwise) and shift everything so that la = 0. Now observe that the beginning of both periods are aligned at first, but then start to differ. This difference is always a multiple of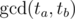 , let this be g. So the difference between the the start of period a (which is also the start of the good days for a) and the start of good days of b is always of the form lb + k·g.
, let this be g. So the difference between the the start of period a (which is also the start of the good days for a) and the start of good days of b is always of the form lb + k·g.
The intersection will be maximized by either making this value the smallest ≥ 0 (good days of b just ahead of that of a) or the largest ≤ 0 (the opposite).
Yes, got it. Thank you!!
Very nice. There was one more tricky idea that D was that you may need to extend the string with common prefixes and suffixes.
Example Testcase: 2
yaa
xaayaa
ybb
xaaybb
Here the answer is not "aa", but "yaa".
Wow, I forgot to exclude variables which don't change while calculating the expansion of the string. Brilliant.
I really hope that wasn't my only mistake...
For my solution, I think it is something like:
Because, my solution will see the first 'b' and convert it to 'd' instead of second 'b', then print NO.
Will the following solution for F work?
Let A be an array of size n. Ai = xor of path from root to ith node. Now answer is just the kth smallest pairwise xor in A.
To do this do a binary search for value of xor. Say x is your current value. Find number of pairwise xors less than equal to x (this should be easy to do with trie). And so on...
Of course, It will lead to TLE or MLE. I didn't think carefully, so spent last one hour for it :)
It seems no chances to pass TL with such solution
Then how to solve it? :p
Test 13 in problem D???
How to solve C?
How to solve problem c? Is there any kind of geometry involved?
Test 7 in C?
I have passed pretests on C with this :)
Can you please tell the logic?
We go through good segments for Alice and Bob, one by one and check the size of the intersection of segments [l0;r0] and [l1;r1]. We iterate 108 times and store the largest intersection.
This is pretty dumb algorithm, but since I wasn't able to come up with a hack case, I've decided to code it.
Why 10^8?
It is the largest number of operations which passes the time limit of 1 second.
Does it work for?
I also have a bit of preprocessing:
I passed C with similar approach but mine gives TLE for more than 4*10^7 steps whiles yours works for 10^8. But i am sure it will fail systests.
I had this idea too, but moving the intervals with binary search for K.
But I can't prove it is correct or incorrect so I didn't code it.
I think your solution will fail on input where one starts with '-' of huge length and another one has small interval (t).
Could you, please, share an example to test the code? I wasn't able to break it ;(
Maybe for this test case
0 1 2
2*10^8+1 2*10^8+2 3
I get an answer of 2 because of my preprocessing
1 2 4
200000000 200000001 4
What's the right answer?
1
Maybe this
0 0 2
10^9-2 10^9-2 10^9
l[0] will reach its max value of 2*10^8 which is < l[1] and hence your answer would be 0 but answer is 1
Shit, I should have used 5·108 as the number of steps ;)
That would have lead to TLE... XO
No, that should be below 1s. The processor speed is 3.4GHz, i.e 3.4 billion of operations per second =)
Look here: https://ideone.com/HVDFuc It runs in 0.88 seconds.
You can use
while(clock()*1.0/CLOCKS_PER_SEC<0.95)...to do as many iterations as possible.That would be too smart for me =)
I have a doubt
Shouldn't we use
Maybe, but I thought that at the beginning of the program
clock()=0.Ah, yes. It says that "
clock()returns the number of clock ticks since starting of the program" sotwill be equal to 0.I thought they run multiple test cases on same program in a loop (without exiting) so I used a variable.
Thanks
this? 0 1 3 903981041 903981051 903981141
I get 0 as an answer. Is it correct?
I don't know the answer, my idea is make your solution get TLE.
How many steps did it take?
ans will be 2
Yes, my code gives 2, once I increase the upper limit from 108 to 5 * 108 ;)
Hmm, that was not a lucky day for me 45531559 ;)
What are the edge cases for problem D. I was getting WA on pretest 8.
This is not an edge case -> the whole idea is wrong.
hey, this is cruel to set such tight constraints in F! Why couldn't you at least allow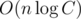 memory pass? :(
memory pass? :(
Who can explain why low number of votes?
Maybe it is because it is clashing with some other contest, or a traditional festival?
how to solve problem B
Initially find the number of segments in O(N). Then per query just check if after incrementing a[p] by D, it affects the segments or not, it can affect in either of the following ways: 1. It can merge to an existing segment(sidewise elements >l), hence no change in the count. 2. It can be a new segment(consisting of itself only), in that case, its sidewise elements have to be <=l 3. It can join two segments into one(when sidewise element>l), in that case, count reduces by 1.
I did the same thing but my code did not work
You continuously failed on test case-3. Please check if you did check for a[p]>l after adding d to it.
yes I did
Can you please share the link to your code.
int main() { std::ios::sync_with_stdio(false); ll n,q,l; cin >> n >> q >> l;
// cout << co << endl; while(q--) { ll a; cin >> a;
}
As far as I can see the checking of a[p]>l has not been given in the last two else if.
I checked it in the first if else only
Whenever you are increasing the count of sequences, you need to check for a[p].
You can also solve using segment tree like this.
It will be useful if you want to query for any intervals.
Used a char array to store the lcp calculated by Z-algorithm on D.
How come I can't find this bug using more than 1 hour during the contest, but spot this instantly after contest......
More important question is how come you couldn't find that Z-algorithm is not needed in D...
Wow how to solve D? Also, more importantly, how to solve D in less than 200 lines?
https://code.re/dvu
In each pair wi ≠ w'i pick the whole substring we should fix (from first to last dismatching letters). If these strings are not same for all such pairs, output NO. Else try to widen this string out by appending maximum possible amount of letters to the left and to the right. At the end check if everything is ok.
size_t lol = s[i].find(A);— isn't this O(len2), so the whole thing is O(n·len2)?Isn't it linear? http://www.cplusplus.com/reference/string/string/find/
I checked that exact website before posting my comment ;p
"Unspecified, but generally up to linear in length()-pos times the length of the sequence to match (worst case)."
Oooh, I didn't read it carefully. Thanks!
It's not guaranteed. But it's also unspecified and I heard that it works very fast in G++ and... Yes, I got AC with it! 45522523
Looks like they just visit all occurences of
s[0]and then match greedily:https://github.com/gcc-mirror/gcc/blob/3f6823abf8d0ce23804dfbfe32c6250824501ef6/libstdc%2B%2B-v3/include/bits/basic_string.tcc#L1189
Hmm. So, weak tests or does it work fast on CF? Or maybe the constant factor is very small?
Just naive search actually doesn't pass. We also found out that string::find gets accepted, but couldn't easily find any test that fails it. Perhaps this is due to memcmp being pretty well optimized.
We tested it. I think just the constant factor being extremely low
For each i, find the smallest interval 0 ≤ l ≤ r < |wi| in which wi and w'i differ (i.e. they are the same outside [l, r]). This interval should have the same length every word (if it exists), and it should contain the same letters for every word. This gives you your initial
sandtNow you would be done, except that there are nasty cases like this:Answer:
But we can print any valid solution, so we just greedily extend
sin both directions while this is possible (i.e. we don't go over the border of a word or consume different letters in different words). Finally just test if thesandtyou found actually work by executing the search and replace on each wi and comparing the result to w'i.My solution:
I looped to n instead of the size of the current string at one point in D. Same thing about noticing immediately after the contest :(
Same here, although such code didn't pass my local tests, so found it fast enough.
was my comment invisible or what :P
I don't understand the logic of counting the same hacking attempt when someone send it accedintally .. why it's not like when someone send the same WA solution twice they don't count the second one
edit: ok take that 50 points :) eventhough I insist it doesn't make sense to count 2 similar consecutive hacking attempts on the same solution
Problem F all the downvoters
Some identical hacks depend on the time the code is hacked, so it does matter.
Thanks for the contest! I liked the problem ideas but thought limits on problems D and F were unnecessarily strict.
D is a very nice conceptual problem, but limits require linear-time string matching (and fast-enough input to read 18 million chars in 1 second). IMO, linear-time matching does not add any depth -- a limit of N ≤ 300, wi ≤ 300 would have all the same conceptual value without requiring book code.
F is similar. Requiring linear-time bucket sort or trie traversal makes the problem much harder but not much more interesting. N < = 105 would allow map / sort / unordered_map solutions to pass without changing the core of the problem. Also, the complexities are hard to distinguish: I've heard of some log-time solutions that snuck under TL as well as some constant-time solutions that went over.
I agree 100%.
Well, one more thing I would appreciate is a guarantee that the answer doesn't change in G if we change some radii by epsilon.
The only geometry that is needed is Minkowski sum and checking that distance from point to polygon is less than d, it's not harder to write it in integers than in doubles.
There is more than one possible approach.
On ACM-style contest this is what we would probably do. But considering that this is a contest where hacks are allowed, we would need to implement such a check in the validator, which would make the validator significantly more complex.
I actually thought about a randomize string matching solution after trying to hack the test case (and fail) :D
I saw some depth there. For example, linear-time string matching using hashes or KMP? Hashes are faster and maybe simpler since we're only checking the first occurrence. And do we really need it, isn't there a stupider algorithm we could use? After all, the problem is quite specific and, more importantly, the lengths of strings are small. How long does it take to write KMP, what are the chances of making bugs compared to other ideas, is it worth risking anti-hash tests, is it worth risking TLE with an optimised bruteforce... all factors to consider. I decided for KMP because it's actually very simple and turned out to be a good choice.
Plus there may be some more straightforward solutions (or parts of solutions). Consider just that the number of forbidden substrings is O(N|w|2).
D was a very evil problem in that there are so many ways to approach it.
As far as I know, strstr works in linear time in GCC and implemented as two-way algorithm.
...and is going to be extremely fast because we're matching cache lines of ~1000 4-byte blocks or ~500 8-byte blocks (depending on architecture).
What's the solution for problem C ?
debugforces
Earning a macbook air with 30 seconds. Glorious !
Apparently pretests in C were very weak. My code even fails to something really simple like
because I shifted by ta instead of the gcd after taking mod gcd :/
Added your test to upsolving
I think he only meant pretests.
Mm, I misread it indeed.
Anyway it is nothing bad actually.
Why isn't the contest open for practice? EDIT: it is now.
How to solve F? Kind of seems impossible to a noob like me
Lol, that was exactly the intention of the probem setters. A noob shouldn't be able to solve a problem F.
You're not answering the question. He isn't saying he should be able to solve it, just stating he wasn't, and asking how to solve it.
I dont give a sh*t if people down vote this but ive seen 2 round of this contest and both of them sucked.
Interesting, for E problem S3 * log(N) is passing easily — 45540761 :)
I rejudged your solution. Sorry, tests in problem E were very weak.
Here is a more intuitive and simple explanation for solution to Problem C which i found after struggling for a day,
Pre-requisite : Understand what we have to do
First of all, if one can make an Alice's interval and a Bob's interval coincide (in the sense that both begin in the same number) then the answer is just min(rb - lb + 1, ra - la + 1) (the length of the shortest interval).
However, this may not be possible. Sometimes it isn't possible for them to perfectly overlap ever(think about it, if you don't get it, continue reading anyway).
We intend to choose lucky intervals(one of alice, one of bob) so as to minimise the difference of the start points of the intervals of alice and bob. Now convince yourself that this will give maximum intersection.
Now the easier part, the solution :)
Consider the start points of two general intervals (one of alice, one of bob).
For alice, start point of general lucky interval is : la + k1 * ta
For bob, it is : lb + k2 * tb
Difference of start points, diff = lb- la + (k2 * tb) - (k1 * ta)
Now, I want you to focus on last two terms of the above expression, they are : (k2 * tb) - (k1 * ta) where k1, k2 are general integers. That's a linear combination of t1 and t2 which always happens to be a multiple of gcd(ta, tb). In fact any multiple of gcd(t1, t2) can always be written as a linear combination of t1, t2(see Bezout's lemma for both these facts).
So we can say that the difference is of the form :
diff = lb- la + k * gcd(ta, tb), where k is yet another integer.
We intend to minimise the absolute value of diff; so we solve the equation, diff = 0(minimise diff) for k. (Note that it may be not be possible for integer value of k, i'm coming on it)
We get after rearranging,
k = -(lb- la) / gcd(ta, tb) (Don't do integer division here).
Of course, since diff = 0 isn't always possible because the start points of alice and bob may never overlap. So this k we have here must be calculated as a float value (use long double), its floor and ceiling are two integer candidates one of which will make the diff value minimum.
So with ceil(k) and floor(k), we obtain two different diff values. For both of these diff values, we calculate the intersection length of intervals [la;ra] and [la + diff; la + diff + (rb — lb)] and print the maximum intersection length for two diff values. (If you don't get this last part, think about it, it's easy, you can ask if you don't get it)
You can refer to my solution here. 45568612
k*gcd(t1,t2)=k2*tb-k1*ta
how do you know that the value
k you got meet that k1,k2>=0
What you just wrote is a Diophantine equation (In case you don't know, read it a bit), These equations have many solutions. Which means for any k, we have many k1, k2 which satisfy the Diophantine equation. K1, k2 come out in form of expressions which depend on integer parameters (After following a standard procedure of solving linear Diophantine equations).I think by manipulating those integer parameters, you would definitely find a solution with non negative k1, k2.
Thank you for your sharing!
I have solved this problem.