Задача A - IQ Тест
Надо просто посчитать количество чётных и нечётных числ. В данных числах может быть или только одно чётное число, или только одно нечётное число --- надо найти его и вывести его номер.
Задача B - Телефонные Номера
Есть много методов разбить на группы из 2 или 3 цифр. Представим один простой вариант: вывести группы из двух цифр пока останется больше чем 3 цифр:
<code>
for( i=0; i<n; i++ )
{
putchar(buf[i]);
if( i%2 && i<n-(n%2)-2 ) putchar('-');
}
</code>
Задача C - Дороги в Берляндии
Входнные данные --- матрица
D, в которой
D[i][j] явлется кратчайшим расстоянием между городами
i и
j. Если создадим новуюу дорогу между городами
a и
b с расстоянием меньше чем
D[a][b], как обновить остальные расстояния в
D?
Пусть матрица
D'[i][j] --- кратчайшее расстояние между
i и
j если добавим в граф новое ребро
ab. Для каждой пары вершин
i, j есть три возможности:
- D'[i][j] не уменьшивается после добавления новой дороги ab: тогда D'[i][j] = D[i][j]
- D'[i][j] меньше чем D[i][j], если мы используем ab. Тогда новый кратчайший путь i, v1, v2, ..., vn, j включает дорогу a, b. Надо пройти вершины i, a, b, j, в этом порядке --- значит новое расстояние будет D[i][a] + length(ab) + D[b][j].
- D'[i][j] меньше чем D[i][j], если мы используем ab. (Заметим, что это не так же, как использовать ab.) Тогда D'[i][j] = D[i][b] + length(ab) + D[a][j].
Поэтому, для каждой новой дороги надо обновить каждое расстояние
i, j в матрице. Тогда надо суммировать все расстояние. Обновить и суммировать --- оба
O(N2) или около
3002 операций. Максмальное количество дорог ---
300, в итоге операций
3003.
Наконец, надо заметить, что сумма всех расстояние может быть больше чем 2^31, поэтому надо посчитать сумму как 64-битовое целое число.
Задача D - Дороги не только в Берляндии
В решении этой задаче используем структуру данных система непересекающихся множеств. Главная идея: структура данных --- множество элементов
x1, x2, x3, ..., xn с каким-то рабиением, которое поддерживает эти операции:
- найти множество, которому принадлежит элемент xi
- объединить любое два множество
Эта структура данных часто появляется в соревнованиях по программированию. Можно писать алгоритм по-разному; вот хороший вариант написан Bruce Merry (BMerry)
здесь.
Каждый день можно закрыть одну дорогу и построить одну дорогу. Поэтому, можно разделить решение на две части:
- Как связать несвязные компоненты графа?
- Как удалить ненужные ребра, не разъединяя граф?
Пусть
build - список дорог, которые надо построить, и пусть
close - список дорог, которые надо закрыть чтобы построить нужные дороги. Можно доказать, что на самом деле, эти списки одного и того же размера. Это следствие того, что связный граф с
n вершинами является деревом тогда и только тогда, когда оно имеет
n - 1 ребёр. Поэтому, если закроем больше дорог, чем построим, тогда граф будет несвязный. Наоборот, если построим больше чем закроем тогда будут ненужные ребра (т.е. граф больше не дерево).
Считаем входные данные:
a1, b1a2, b2...
an - 1, bn - 1Можно доказать, что ребро
(ai, bi) ненужные тогда и только тогда, когда вершины
ai, bi уже связаны ребрами
(a1, b1), (a2, b2), ..., (ai - 1, bi - 1). Т.е, если
ai, bi принадлежит одной и той же компоненте связности без ребра
(ai, bi), тогда не надо добавить
(ai, bi) в граф. Используется система непересекающихся множеств:
<code>
for( i from 1 to n-1 )
{
if( find(
ai)=find(
bi) ) close.add
(ai, bi);
else merge(
ai, bi);
}
</code>
Иначе говоря, считаем каждую компоненту связности как множество в разбиении вершин. Структура данных помогает нам найти то, в каком множестве лежат элементы
ai, bi. Если они в одном множестве, тогда можно закрыть дорогу
(ai, bi). Если они лежат в других множествах/компонентах, тогда можно объединить эти множества.
Вторая задача - связать несвязные компоненты - тоже решается системой непересекаующихся множеств. Проходим все вершины; когда найдём компоненту несвязную с первой компонентой, тогда добавим ребро между ними.
<code>
for( i from 2 to n )
if( find(
vi)!=find(
v1) )
{
then merge
(v1, vi);
build.add
(v1, vi);
}
</code>
(Кстати, у меня вопрос --- на русском языке есть соокращение или короче форма "система непересекающихся множеств"? Моим пальцам больно печатать ваши огромные русские фразы =P)
Задача E - Тест
Я решил эту задачу хешированием. Так как в хешированиях могут существовать коллизии, на самом деле моё решение "неправильно", но оно всё равно правильно отвечает на все тесты =P
Пусть входные строки
s0, s1, s2. Постараемся найти кратчайшую строку, которая содержит
s0, s1, s2. Пройдём все порядки
s0, s1, s2 и поищем длинейшее перекрытие в конце строки
a и начале строки
b. Польный перебор конечно требует слишком много времени. С другой стороны, херширование может решить за
O(n) операции, где
n = min(len(a), len(b)). Моя хеш-функция - полином
hash(x0, x1, ..., xn) = x0 + ax1 + a2x2 + ... + anxn. Этот полином удобный в этой задаче потому что он имеет следующее свойство:
Если известно
hash(xi, ..., xj), тогда можно за
O(1) посчитать следующие значения:
- hash(xi - 1, xi, ..., xj) = xi - 1 + a × hash(xi, ..., xj)
- hash(xi, ..., xj, xj + 1) = hash(xi, ..., xj) + aj + 1 - i × xj + 1
Т.е., если известно значение хеш-функции какой-то подстроки, легко посчитать значение соседных подстрок. Для строк
a, b, посчитаем значения хеш-функций подстрок в конце
a и в начале
b. Если они равные для подстрок размера
n, тогда значит, что (может быть) есть дублирование
n характеров в
a и
b.
Поэтому, пройдём все порядки
s0, s1, s2, и попробуем связать строки вместе. Осталась одна проблема --- если
si подстрока
sj и
i ≠ j, тогда можно пропустить
si. Используем хеширование быстро решить,
si подстрока
sj или нет.



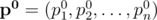 -- заданный вектор вероятностей успеха ядр и
-- заданный вектор вероятностей успеха ядр и 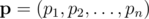 -- другой вектор вероятностей. Пусть
-- другой вектор вероятностей. Пусть 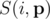 -- вероятность, что точно i ядр будут успешными, допустя что ядро i будет успешным с вероятностей pi. Тогда мы хотим найти максимум функции
-- вероятность, что точно i ядр будут успешными, допустя что ядро i будет успешным с вероятностей pi. Тогда мы хотим найти максимум функции
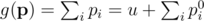
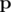 должен удовлетворить условию
должен удовлетворить условию 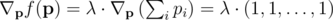
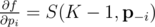
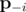 -- вектор вероятностей без pi, т.е. (p1, p2, ..., pi - 1, pi + 1, ..., pn). Иными словами, частная производная f по переменной pi -- это вероятность, что K - 1 других ядр будут успешными (без ядра i).
-- вектор вероятностей без pi, т.е. (p1, p2, ..., pi - 1, pi + 1, ..., pn). Иными словами, частная производная f по переменной pi -- это вероятность, что K - 1 других ядр будут успешными (без ядра i).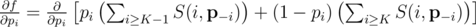
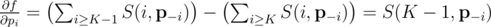
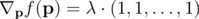 -- установить все pi равные друг друга. Но это невозможно потому, что мы не можем уменьшить pi меньше чем p0i. С учетом граничных условий, мы имеем для каждого ядра i три вариантов:
-- установить все pi равные друг друга. Но это невозможно потому, что мы не можем уменьшить pi меньше чем p0i. С учетом граничных условий, мы имеем для каждого ядра i три вариантов:






