


Meta Hacker Cup Round 2
Good morning! Meta Hacker Cup Round 2 starts on Saturday, October 21st, 10 AM Pacific in under 26 hours! You're automatically registered for Round 2 if you scored at least 4 points in Round 1.
Important info:
- You'll qualify for Round 3 if you place in the top 500 in this round.
- If you place in the top 2000 of this round, you'll win a limited edition Hacker Cup t-shirt.
- If you qualify for Round 3, and you place in the top 200 of Round 3, your shirt will have a special "Top 200" badge on it.
You can find more info about T-Shirt details on this post. Good luck, have fun, and we'll see you on the scoreboard!






hopefully server works perfectly!
In Round 1 for Problem B1 there the T was ~ 960 . In my output.txt file it printed only upto 330 lines. I had already ran the command to make the stack size unlimited in Mac terminal before compiling the code and executing the .exe file. What should I do to make sure that this does not happen tomorrow, like the stack size issue is what worries me the most.
https://codeforces.com/blog/entry/120772 This might help.
I tried that command to make stack size max. possible during the competition still no effect.
AFAIK on macOS there are some issues with large stacks
https://stackoverflow.com/questions/13245019/how-to-change-the-stack-size-using-ulimit-or-per-process-on-mac-os-x-for-a-c-or
Mine also did not work on R2-C due to 1M depth recursion, and I had to use Linux machine. On linux you can do ulimit -s unlimited and it works perfectly.
I really hope to qualify to the third round
I really hope that the input/output example will be visible tomorrow. Unlike the past round, I don't want to blindly guess how to output the solution.
btw is it rated?
I believe the reason that the samples did not show in Round 1 is because the page does a DB query to retrieve the sample cases (after it's initially loaded), so when the backend was down due to load issues, the queries for the sample cases would fail as well. Notice that after the issue was fixed, samples loaded correctly.
Thanks for nice explanation m8!
Again a request to link the starting time to the Event Time Announcer tool instead of the countdown. It's extremely inconvenient to figure out the starting time using the countdown.
clist.by
Thanks for the suggestion. I updated it.
Any chance we could get the scoring distribution, or at least the number of problems, before the contest starts? As a personal preference I always like having problem scores in advance in order to make a plan for the contest, but more importantly knowing the number of problems is helpful to me in setting up my file system ahead of the competition.
damnnnnn, i fu*ked up on problem a2, didn't notice constraint of it and thought it was similar to a1 and when my timer was running out and i didn't get output, i was like: come back again next year. Till then bye bye.
same to me Bro ! got runtime error while the timer was running .
On a Quest to become more Pro, Why don't you print something interesting on the t-shirt.
Counterpoint: I personally typically cringe at "inspirational" quotes printed on shirts (and e.g. I don't wear the Kotlin Heroes T-shirts outside for this reason). I like the current Hacker Cup shirt design and hope that the organizers don't make changes intended to make it more attention-grabbing.
What do you even mean by "make it more attention-grabbing"? I've stopped counting how many times I was asked by totally random people whether I can hack sites other than Facebook as well. Most often I don't remember what T-shirt I'm wearing at the moment, so these questions surprise me immediately.
Your experience sounds different from mine; nobody has ever really mentioned my MHC shirts when I've worn them around.
I mainly mean that I would prefer the current shirt over one that includes e.g. a quote/slogan, a design/pattern that isn't at least somewhat subtle, etc.
Don't know why, maybe cultural difference, maybe just pure randomness of this happening. Just to be clear, it's not that people stop on the street and ask about it, last year I was asked by 3 different cashiers in some random shops and 1 security officer in the airport. So it's usually a case where you already have an eye contact, but instead of asking "How are you doing?" they were saying "Do you hack Facebook?".
what should i do, if my website freezed and was unable to submit due to that?, i have submitted a clarification, lets see
Did anyone else get missing test cases for input file for A2? I got just around 50% of the test cases.
mine just printed around 41 of them idk if my code crashed or the test cases had issue with the test case so can't say for sure. Also didn't get any error, the code compiled perfectly fine for me just didn't get all the outputs.
There aren't missing cases in the input, but many people's source code is crashing partway through on their local computers because they set their stack sizes incorrectly, not because there is any system issue. We have explicitly warned against stack size issues in the past, as well as in our FAQs, and problem D of the practice round was designed explicitly to make sure people knew this.
While I agree that stack overflows are the contestant's fault, I think designing problem D of the practice round with this in mind (which most newbies, the people most likely to encounter such issues, aren't going to attempt to solve anyway) was a mistake. You probably wanted to put such a pitfall in A, with a huge red warning/FAQ about it that hopefully people wouldn't ignore.
What happened to tourist?
He's competing in WPC and earned a bye from round 2 in round 1.
Why didn't you make a system with tests and checkers?
Good round, huge improvement over the last one.
I got WA on everything except D and qualed bruh
Feedback on the round:
A: Fine as the easy problem.
B: Not my favorite problem. The observation that any answer that exists must be less than 2N is nice enough, but from there the problem feels like a couple of disjointed exercises tacked on together in a contrived way. Neither the step of checking whether the inequality constraints are respected using a sliding window-style approach nor the standard string exercise to check if A is the reverse of B felt especially interesting, and in the end I was left wondering what the point of doing all that was.
C: Nice problem; thinking through a way to handle the DP that was provably O(n log^2 n) was pretty interesting, and after all that the implementation isn't bad at all (though apparently, my solution is different from what was intended). It wasn't obvious to me that we had to have some friend starting at each leaf (and no friends starting elsewhere) until I read the formal version of the statement, which clarified that we are partitioning a tree into edge-disjoint paths; I think the flavor text could have been made clearer/more consistent with the formal statement of the problem.
I made an error in my implementation that degraded the complexity to O(n^2), and thus ended up spending much of my submission window frantically trying to find the bug (and eventually succeeding). I found this process very satisfying, and situations like this are one of the reasons why I hope Hacker Cup doesn't change its format.
(Sidenote: I do think MHC could do a better job communicating the intricacies of the format to new contestants. One example might be providing instructions on the contest website to increase the stack size limit for some commonly used operating systems and offering a year-round practice contest involving a single easy problem, perhaps even with code provided by the organizers, that requires contestants to set a large enough stack size to get AC. Depending on how paternalistic the organizers want to be, ACing this example problem could be required in order to register.)
D: Fine problem. I liked the red herring of requiring K <= 20, which doesn't make the problem any easier but does make solutions independent of K a bit more suspect, encouraging contestants to prove that their solution actually works rather than going for proof by validation tests. The part after realizing that the requirement is just for the GCD of all chosen numbers to be a factor of D is a bit on the standard side, but I haven't seen this exact variant before (though I have seen "make sure the GCD of all chosen numbers is exactly K for some fixed K" many times). I didn't think this was nearly difficult enough to justify the 41-point allotment; I felt that it was on par with C, and I think 8/9/21/31/31 would have been a reasonable score distribution.
Overall, I enjoyed the round, but I felt like it was substantially easier than Round 1. That said, it does look like the round was hard enough to plausibly distinguish the top 500 from the rest of the participants, so it seems things turned out fairly well.
Note: A friend informed me of a clever solution to B using the idea that if a solution exists, then after about $$$n/2$$$ more rotations, all elements of $$$A$$$ will exceed all elements of $$$B$$$. This makes me like the problem a bit more, but I also feel like there wasn't enough incentive to make this observation since I don't think it actually speeds the implementation up much conditional on having a good hash template.
Agreed that B is not my favourite problem, there's just too many details and the verification test was too weak that it didn't catch a very obvious mistake in my code.
By the way, C can be solved in $$$O(n\log n)$$$ time by a simple segment tree, I don't know what is the intended solution though.
It looks like the intended solution is $$$O(n)$$$, basically by merging vertices with outdegree 1 with their children and then running a brute force for each word occurring a number of times greater than or equal to the number of leaves. As with B, it's too bad that the incentive to come up with the intended solution wasn't strong enough, although in this case I think the alternate approach I implemented was about as interesting as the intended solution.
Mine uses small-to-large merging to maintain the set of words that are known by the remaining path at the current vertex, iteratively removing words from our answer set when we find that two children of some vertex both don't know them. It can be proven that iterating over the remaining words each time we merge two vertices is efficient (as each time we keep a word, it must have been used in one of the children and that copy of the word will be discarded afterwards), so the complexity is bounded by the cost of small-to-large merging.
I liked B with regards to the points it gives you. I don't know what you mean by "standard string exercise to check if A is the reverse of B", I used naive algorithm there, which should be enough if you check previous higher-lower conditions in advance. This observation + sliding window implementation is ok for the second easiest problem, IMO.
See this comment; the problem can be solved without making this observation by copying a hashing template. Doing so doesn't meaningfully increase the length of code I have to type (again, not counting copying the template), meaning that there wasn't actually an incentive to make this observation in order to save time.
I would like this problem much more in a hypothetical world in which the observation was required to reach the solution. In this case, however, not only is directly implementing what the problem says without thinking about any potential observations a possible solution, it's actually no more time-consuming to type than the clever solution is.
For D I do not understand that the solution is independent of k. Can you please explain it.
It depends on k, just doesnt use the fact that k <= 20.
The condition is effectively that gcd(chosen numbers by both players) | D. Using some inclusion exclusion, you can find the number of all subsets of size k which satisfy this.
Then just output this number * k! (The ways alice and bob could play to get these subssets)
For a proof that the condition is sufficient, check the editorial.
Thank You this clears my doubt
Me when I make round 3 by knowing morbius inversion but not DFS:
Thank you for the round!
Also, D < B < C imo.
Based on difficulty or how much you liked the problems?
Based on difficulty. The liked order on these three problems for me is inverse, I would say
I would even say D < A.
d<b ????
I misread the third problem and was solving the wrong version for quite some time. I was not able to solve it, so I am interested in whether somebody knows how to do so.
I read it as if when a person reaches an already visited page, they stop, but they nevertheless still read this page. So the paths are edge-disjoint, not vertex-disjoint. As far as I understand, in this version, the fact that a topic is mutually-learnable is equivalent to the fact that for any pair of leaves, this topic appears on the path between them (plus on any path from a leaf to the root). I don't know how to solve it in time faster than something like $$$O(nm/w)$$$. Does anybody have any ideas?
So far it seems that my solution works for this version with minimal modifications.
For each topic and for each leaf, we find the closest vertex on the path to root from this leaf with this topic. Now for the problem as stated, we need to make sure those vertices are all different. And for your version I guess we need to make sure that whenever we have collisions, they all come through different direct children of the collision vertex?
My solution for the real problem relies on the fact that the number of these lowest chosen vertices should be at least the number of leaves in the tree. In the incorrect version, it is not true anymore because a single vertex can facilitate all its children. Maybe your solution is different, and can handle it somehow?
Oh, good point! This would be quadratic for my solution too.
In my solution for every vertex V having topic T I said that subtree rooted in V is "covered" with regards to T if the amount of leaves in V-subtree, not covered by its children, is at most 1. If there are more than 1 non-covered leaf, you can immediately mark topic as invalid. Then you can run one post-order DFS to figure out those subtrees covered with respect to some topic. To see whether a topic should be added to the answer at the end you iterate all topics and check same criteria with regards to the entire tree, but this time the amount of non-covered leaves should be exactly 0. This covers both the scenario where topic is present on the root node and where it isn't.
You can just turn this into the vertex-disjoint version by splitting each edge into a path of length two, and moving the topics of each original vertex to each of its newly created children.
EDIT: oh just realized this may result in a blow up in the sum of the $$$M_i$$$'s
I guess the solution with small-to-large should work:
Keep a list of all topics covered under the main path of some node $$$v$$$. If $$$v$$$ has no more than one child, merge and add the current topics. Otherwise, keep all topics that appear in $$$\geq deg(v)-1$$$ children, along with the topics of $$$v$$$ and discard the topics that appear in $$$\leq deg(v)-2$$$ children and not in $$$v$$$.
The bolded part is the difference between the original solution and the modified solution. Just like in the original solution, you need to avoid iterating all children only in the first case (all else amortizes).
Hi,
I'm 501st in the contest, but I had two submissions sent in via the clarification system since I was unable to download the inputs. Can those submissions be considered somehow? My username is socho.
Thanks!
Upd: Thanks a lot, the submissions were added in!
omg. almost failed Hacker Cup again this year because of StackOverflow in A2(2 times failed in previous years). i changed my laptop and visual studio and old methods did not work( but submitted B 10 minutes before contest end and got AC)
Was C solved with something like dp for the sets of topics with small to large optimization?
No
It could be, although the intended solution is much easier
Deleted
Can B be solved with just a difference array? For each index find the spans where it is going to fit in the right place + an extra option to be placed in the middle when $$$N$$$ is odd (options to fit are ranging from $$$0$$$ to $$$2 \cdot N - 1$$$ operations). I got stuck with a bug and couldn't implement it properly, unlucky.
UPD.: I just realized that in case of an odd $$$N$$$ to account for extra cases when a pair of elements gets placed in the middle I was increasing by one the elements of the difference array, and not just a separate array, rip.
UPD2.: And it passed the tests, although I really didn't enforce the third condition, only for the halves to be greater/less than each other and the count of all elements to be an even number.
I had a different solution to C. For each string, we iterate over the nodes that contain it in reverse order of depths. Realising the leaf we choose to extend the path down from this node to doesn't matter, we simply check that there is at most one such leaf, and indicate to future nodes that a leaf in the current node's subtree has been satisfied. We do this with a segment/fenwick tree.
Exactly same as mine! Unfortunately couldn't submit it due to stack size issues :( Got AC after contest
Same!! I didn't qualify because I mistyped compilation, AC one minute after the contest...
Am I the only one who didn't understand the statement of problem B. What does it mean that after each second A1 will move to end of B ?
It literally moves.
Example:
A = {1, 2, 3, 4}
B = {5, 6, 7, 8}
after 1 second
A = {2, 3, 4, 5}
B = {6, 7, 8 ,1}
First element of A is appended to B. First element of B is appended to A. And everything else moves left.
Problems feedback:
A. First looked too scary for A but ended up being a nice little problem.
B. For me personally looked like a problem with no ideas. Just apply some algorithms to do exactly what is written in the statement (we can just write ABA as one array and need to find a palindrome of length 2n in it which can be done using Manacher's algorithm, the inequalities are also easy to check).
C. From reading other comments and looking at other solutions I am not sure whether my solution is so common (UPD: It seems like it's actually the solution from the editorial). Though it is super easy. For a fixed topic for each leaf, we should look at the first vertex on the path to the root that contains this topic, and for all leaves, these chosen first vertices should be different. We can contract all the bamboos (paths of vertices with a single child), and after that the problem is obvious: if some topic appears in fewer vertices than the number of leaves there are, it can not be mutually-learned. Otherwise, we can just solve the problem in linear time for this topic (just go up for each vertex until you find a visited vertex or a vertex containing this topic) because in a tree where each vertex has at least two children, the number of vertices is at most twice the number of leaves, so the time complexity will be $$$O(M / n \cdot n) = O(M)$$$ where $$$M = \sum m_i$$$. I liked the problem.
D. Not a bad problem but a couple of standard observations and a classical algorithm do not seem worth 41 points.
I have a question for C's editorial. It states:
How would this tree be compressed?
(you can imagine $$$N = 10^6$$$ nodes there)
Every non-leaf node has two children, so it cannot be compressed anymore, right? But if it can't be compressed, then it does not satisfy that constraint of "L, L/2, ..., 1". What am I missing?
Your tree would not be compressed, but it has $$$2L-1$$$ vertices, so it will not break the overall complexity of the solution.
I agree that the proof of the bound in the editorial is not correct as stated. However, we can show by induction on the height of the tree (and by several other means) that a tree with $$$L$$$ leaves such that each non-leaf vertex has at least two children can have at most $$$2L-1$$$ vertices. Indeed, if our tree is simply one vertex, the claim clearly holds.
Otherwise, suppose the claim holds for trees of height up to $$$d-1$$$ and consider a tree of height $$$d$$$. The root of this tree must have at least two children. Say that there are $$$K$$$ such children and their corresponding subtrees have $$$L_1, \dots, L_k$$$ leaves. Then the total number of vertices in each subtree is at most $$$2L_i - 1$$$ by induction, so the total number of vertices in the tree is bounded above by $$$1 + \sum_{i = 1}^K (2 L_i - 1) \le 1 + \sum_{i = 1}^K (2L_i) - 2 = 2\sum_{i = 1}^K (L_i) - 1$$$, using the fact that $$$K \ge 2$$$.
Meanwhile, the number of leaves in the new tree is exactly $$$L = \sum_{i = 1}^K L_i$$$. Thus, the number of vertices in the tree is at most $$$2L - 1$$$, as desired.
Got it, thanks a lot for your explanation!
There's an extremely simple solution to C which doesn't involve contracting edges or dp or clever optimizations, just a DFS:
At the end a topic is possible if it has not been marked impossible and has 0 unpaired leaves. The complexity is O(n + sum(m)).
Oh wow, that's a really neat solution! Took me a while to understand it myself 😓. Thanks for sharing!
I'm getting Presentation Error for A2. I don't know why. The output file looks correctly formatted. Can somebody help me out?
This is my output file for A2
Can we get the certificate without rank in practice round(if we didn't participate/make submissions in that)?
No, you shall take your certificate with a 4k placement in the practice round and you are going to treasure it like nothing else.
Regarding C, does this claim work when the tree is skewed like this?
Edit: Nevermind, I'm dumb. We should care about the relative levels and the number of nodes is still bounded by $$$O(L)$$$ anyway.
See here.
On macOS, apparently
sudo ulimit -s unlimiteddoesn't change the stack size and doesn't print any errors. After my submission window for C had passed, I found out that these compiler flags worked:-Wl,-stack_size -Wl,20000000. Cost me round 3 qualification :(Stack Overflow in A2. TT
I use codeblocks, how to increase stack size?
don't use codeblocks
(hashtag)pragma comment(linker, "/STACK:268435456");
Maybe not standard solution for B and C, so just share some intuitions.
B: First it is trivial that $$$2N$$$ rounds form a cycle. Then my observation is that constraints 1 & 2 are strong enough so that only $$$O(1)$$$ is valid (without checking constraint 3). This is because we are constantly comparing the same pair of $$$(A[i], B[i])$$$ even if it is rotated to the tail of array. We can imagine a separation position where before it has $$$A[i]<B[i]$$$ and after it has $$$A[i]>B[i]$$$, only when this separation position coincides with $$$N/2$$$ can constraint 1 & 2 be satisfied. So $$$O(N)$$$ check for constraint 3 is acceptable, and constraint 1 & 2 can be checked via prefix sum or something similar.
C: An obvious observation is that "a set of paths where each node has only one son" is equivalent to "a single edge", because we will not split such path into smaller sub-paths. Then we can simply merge these paths by merging the topics alongside. After such modification, the tree becomes more compact, as every non-leaf nodes has at least 2 sons, then the number of non-leaf nodes is no larger than number of leaves.
Then we can justify that the number of occurrences of a valid topic should be larger than the number of leaves, because there is one disjoint-path that starts from each leaf. So there are at most $$$O(\sum_i M_i/ leaf)$$$ possibly valid topics, and we can run a simple DP to check if it is possible to assign disjoint-paths, which is $$$O(leaf \log leaf)$$$ (there is log term because I used std::set to check if topic is contained at each node).
These aren't the final rankings it seems? A number of people seem to be mentioning submission through clarification section which aren't being reflected atm?
Also I'm not an expert in Go (and I would like if someone could clarify this for me), but are moves placing a black stone in positions like this:
or
legal moves? I tried to skim through the rules of Go, but still haven't figured what moves are legal and not (in other words: is placing a black stone on the vacant spots in examples above a "suicide" move, or would it actually capture all of the stones in the real game of Go).
UPD.: I've seen one source mentioning "enforce the capture rule before the suicide rule", so I guess it does make sense in this case.
Yup, it's valid in the real game to play a black stone in those cases. You can "suicide" as long as you capture at least one stone.
The only invalid moves in Go are "suicides" that don't capture any stones (though some jurisdictions do allow such moves -- such a rule almost never matters but has a couple funny edge case implications), and moves that return the board to the state it was just in (see the "Ko rule", and also "Super-ko rule").
Can someone please please tell how to change the hard limit of my stack on M2 Mac, it is maxed out to 64MB. I thought ulimit -s unlimited does the trick but it doesn't raise the stack size to over 64MB. Caused me lot of sadness 。°(°.◜ᯅ◝°)°。 during the contest. The trick mentioned in nor's blog doesn't work on my arm based processor.
me too, I couldn't upload problem A2,I'm using windows 10, and preferred language is C++.
Try this.
g++ -Wl,--stack,1073741824 solution.cpp -o solution gives me error in compiler clion
oohoh, during the whole 5-6 min window, I saw the below command somewhere and tried to use it
g++ "-Wl,--stack,0x20000000" a2.cpp -o a2
I just had to do remove the double quotes,, 。°(°.◜ᯅ◝°)°。.
Thanks!!
Try this. I don't have a M2 Mac, but it works on my ARM server.
Also, it should work with any sizes of stack size.
I get this error running on my terminal
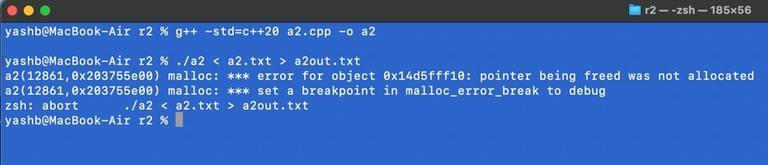
nice catch. it should be fixed, but it's a bit long now. :(
Is plagiarism checks for round 2 finished?
There is actually no reason to use mobious function for problem D. Let $$$f(x)$$$ be number of subsets with $$$GCD = x$$$, then we just compute $$$f$$$ using the following way:
Answer is sum of $$$f(d)$$$ over all divisors of $$$D$$$.
the stack limit really got me today in A2. hopefully MHC will come back with better judge system next year.
I code on mac, and send the code over whatsapp to submit using a Linux laptop, but It's more of a Mac problem not MHC problem.
It's not a Mac problem you can increase stack size in Mac easily. Been doing it since hacker cup 2014 or something.
yeah same, got seg. fault with the timer running went to cf post as fast as I can and copied code to increase Stack limit and submitted in the last 10 sec, uuuff.. that was close
I also got seg fault but I just declared the arrays global and it got resolved. I didn't use recursion.
I used enhanced Manacher algorithm for B:
I prepared input as follows: C array where Ci = Ai — Bi, then D array = C + (C reversed and negative) + C
Then ran algo on D array with enhanced condition: left_value < 0 && left_value == -right_value. If found palindrome length >= N, then we found center of this palindrome and we can calculate start index of palindrome(meaning answer = needed seconds to get logo). The only thing to care about is that center should be equal to 0 for odd N