


Hi everyone! 2 years ago Logvinov_Leon asked about way to get the suffix array from suffix automata. Oddly enough, he had not received answer. However, as you may have noticed, I'm interested in the topic of transformations of some string structures to others, so I decided to shed some light on how this is done.
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | jiangly | 3578 |
| 4 | orzdevinwang | 3570 |
| 5 | Geothermal | 3569 |
| 5 | cnnfls_csy | 3569 |
| 7 | tourist | 3565 |
| 8 | maroonrk | 3531 |
| 9 | Radewoosh | 3521 |
| 10 | Um_nik | 3482 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 161 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 152 |
| 8 | SecondThread | 146 |
| 8 | orz | 146 |
| 10 | pajenegod | 145 |
→ Find user
→ Recent actions






Hi everyone again! Recently, solving the problem 1937 from Timus (by the way, I recommend it to you too! It is a great opportunity to improve yourself in string algorithms), I was faced with the necessity of finding all subpalindromes in the string. Experienced programmers already know that one of the best algorithms for this is Manacher's algo that allows you to get all subpalindromes in compressed form without any additional structures. The only problem — the algorithm is kinda hard to implement. That is, its idea is simple and straightforward, but the implementation usually are heaps of code to the widespread consideration of where to write +1, and where -1.
Hi everyone! The countdown is on. Round 1B begins in under 24 hours. If you preferred to sleep instead of competing in round 1A (just like me!), then this round is for you! The top 1000 contestants from sub-round will advance to Online Round 2 and won't be able to compete in further sub-rounds.
I remind you that round will take place on Saturday, May 3 at 16:00 UTC at the site, that everybody knows.
Hi everyone! I was always wondered how cleverly interwoven so-called string algorithms. Six months ago I wrote here article about the possibility of a rapid transition from Z-function to prefix-function and backward. Some experienced users already know that such transitions are possible between the more complex string structures — suffix tree and suffix automaton. This transition is described at e -maxx.ru. Now I would like to tell you about such data structure as a suffix tree, and share the simple enough (theoretically) way of its fast building — obtain a suffix tree from suffix array .
Hi everyone! I think many of you know about such data type as set. It must support such operations like:
- Insert an element into set;
- Check if the set contain some element;
- Delete element from set.
If we talk about ordered set, then elements (what a surprise!) must be kept in some order. As I think, there is also very important next operations:
- Find the k-th element in a set;
- Find the order of element in a set.
Most of all, for the implementation of such functional some may use binary balanced trees (AVL- tree , red-black tree , cartesian tree , etc). However, in this article I would like to talk about some of the features in the implementation of an ordered set with other structures. In particular, I'll show the implementation with the segment tree and with the Binary Indexed Tree (Fenwick tree). But I just want to note that it only allows you to build the set of natural numbers. For all other types of elements such methods will not work :(
The basic idea:
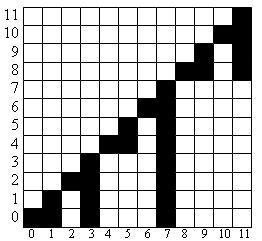 Let the index of cell in the array be the value of element in the set and let the value in the cell be the amount of element in cell. Then we can easily do all required operations in the logarithmic time. Really, the insertion of element x in the set is the same as increment of arr[x]. Deleting of element is the same as decrement of arr[x]. To check if the set contains element we should check if arr[x]>0, i.e. sum(x, x) > 0. We should also mention the operation of finding K-th element. To do this we will have to use the technique of binary expansion. In the segment tree we should store the sizes of the subtrees, like in BST, and in binary indexed tree we can watch to the following image showing the distribution of elements in tree and derive an algorithm:
Let the index of cell in the array be the value of element in the set and let the value in the cell be the amount of element in cell. Then we can easily do all required operations in the logarithmic time. Really, the insertion of element x in the set is the same as increment of arr[x]. Deleting of element is the same as decrement of arr[x]. To check if the set contains element we should check if arr[x]>0, i.e. sum(x, x) > 0. We should also mention the operation of finding K-th element. To do this we will have to use the technique of binary expansion. In the segment tree we should store the sizes of the subtrees, like in BST, and in binary indexed tree we can watch to the following image showing the distribution of elements in tree and derive an algorithm:
int get(int x)
{
int sum=0;
int ret=0; // Number of element in array, for which the sum is equal to sum
for(int i=1<<MPOW;i && ret+(i-1)<N;i>>=1) // Loop through the powers of two, starting with the highest possible
{
if(sum+arr[ret+(i-1)]<x) // Trying to expand the current prefix
sum+=arr[ret+(i-1)],
ret+=i;
}
return ret;
}
Easy to see that while using this approach ret always has a value such that the next time a number from the interval [0; ret] will be met not earlier than at ret + i, however, due to decreasing of i, we will never reach this point, and therefore, none of the elements in the prefix will be counted twice. This gives us the right to believe that the algorithm is correct. And the check on some problems confirms it :)
The basic idea is presented, for now let's talk about the advantages and disadvantages of this approach.
Pros:
- We can write it really fast;
- Intuintive (especially in the case of the segment tree);
- Works fast (in practice often overtakes BST);
Contras:
- Limited functionality (supports only integers in the set);
- In its simplest form takes O(C) memory, where C — the maximum possible number in the set;
The second drawback is VERY essential. Fortunately, it can be eliminated. You can do this in two ways.
- Compression of coordinates. If we can solve the problem in an offline, we read all queries and learn all possible numbers, which we will have to handle. Then we sort them, and associate smallest element with one, the second smallest — with two, etc. This reduces memory complexity to O(M), where M is the number of queries. However, unfortunately, it does not always work.
- Dynamic growth of the tree. The method is not to store int the tree the vertices, which we do not need. There are at least three ways to do this. Unfortunately, for binary indexed tree there is only one of them is suitable. The first option — to use a hash map. Bad, very bad option. More precisely, with the asymptotic point of view it is good, but the hash map have very large constant, so I do not recommend this method. Unfortunately, it is that only way that we can use in BIT :) . The second option — extension with pointers. When we need a new tree vertex, we simply create it. Cheap and cheerful. However , it is still not the fastest option. The third option — statically allocate a block of MlogC vertices, and then for each vertex store the indexes of its children (as in trie). In practice, it is the fastest way. Memory complexity is the same in all three methods and is reduced to O(MlogC), which are generally acceptable.
I hope that I was interesting/useful to someone. Good luck and have fun! :)
P.S. Sorry for my poor English. Again ;)
Hi everyone! Many saw entry of user Zlobober which stated that the Thue-Morse string with terrifying force knocks hash modulo 2^64 . Single hashes were too unsafe because of the birthday paradox. The only remaining salvation from infernal suffix structures was double hashing. However, soon it will come to an end. Thoroughly studying Thue-Morse string and its possible modifications, I came to the conclusion that the test that breaks even double hash solutions is possible.
Here I described in detail the construction of the test, its use against real solutions from various contests and proof of its work.
Now I propose to users of codeforces to discuss what to do in this situation. Is there really no more ways to solve the problems with polynomial hash? Who has any thoughts on this?
Hi everyone! After a relatively long lull, I decided that my contribution growing too slowly the hour has come to please you with another article in the blog :)
2 months ago user Perlik wrote an article, in which he described a very interesting STL implemented data structure that allows you to quickly perform various operations with substrings. Some time after I tested it on various tasks and, unfortunately, tend to get a negative result — rope was too slow, especially when it came to working with individual elements.
For some time, I forgot about that article. Increasingly, however, I was faced with problems in which it was necessary to implement set with the ability to know ordinal number of item and also to get item by its ordinal number (ie, order statistic in the set). And then I remembered that in the comments to that article, someone mentioned about the mysterious data structure order statistics tree, which supports these two operations and which is implemented in STL (unfortunately only for the GNU C++). And here begins my fascinating acquaintance with policy based data structures, and I want to tell you about them :)
Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Apr/29/2024 00:34:47 (k3).
Desktop version, switch to mobile version.
Supported by
