


Всем привет! Недавно меня заинтересовала такая задача: дано дерево с корнем в вершине 0. Поступают запросы двух видов.
- Добавить к вершине k сына.
- Выдать номер предка вершины k, у которого высота равна h.
Вершины пронумерованы в порядке добавления.
Пока что я знаю только два метода решения:
- Двоичный подъём. Ну тут всё очевидно,
 времени и памяти.
времени и памяти. - С помощью индексированного двоичного дерева поиска (например, неявная дерамида) поддерживаем эйлеров обход графа. Далее либо сводим к k-ой порядковой статистике на префиксе, либо храним для каждой высоты список вершин и находим нужную бинарным поиском. Это потребует O(n) памяти, но времени
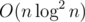 (возможно, при грамотной реализации можно и , но я точно не знаю), ещё и с большущей константой.
(возможно, при грамотной реализации можно и , но я точно не знаю), ещё и с большущей константой.
Интересно то, что оба метода подозрительно похожи на LCA. В связи с этим возникает вопрос — может, задачу можно как-то свести к LCA непосредственно? Ну и, конечно, интересно, какие ещё есть способы решения этой задачи, в том числе и в оффлайне.






 Пускай индекс элемента в массиве (назовём его для удобства
Пускай индекс элемента в массиве (назовём его для удобства 
